설치 방법은 아래 공식 문서를 참고했다.
https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano/#install-necessary-packages
NVIDIA Jetson Nano Deployment
Detailed guide on deploying trained models on NVIDIA Jetson using TensorRT and DeepStream SDK. Optimize the inference performance on Jetson with Ultralytics.
docs.ultralytics.com
https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
PyTorch for Jetson
Below are pre-built PyTorch pip wheel installers for Jetson Nano, TX1/TX2, Xavier, and Orin with JetPack 4.2 and newer. Download one of the PyTorch binaries from below for your version of JetPack, and see the installation instructions to run on your Jetson
forums.developer.nvidia.com
먼저 JetPack SDK와 JetPack Components들 그리고 DeepStream SDK가 제대로 설치되어 있어야 한다.
이를 위해서 SD카드 이미지를 사용하는 방법 그리고 SDK Manager를 사용하는 방법 두 가지가 있는데 이전 글에서 SDK Manager를 사용하는 방법에 대해 다른 글로 정리했었다.
1. PyTorch 와 Torchvision 설치하기
그 전에 PyTorch와 Torchvision이 뭔지 간단하게 살펴보자.
PyTorch: 파이토치 파이썬 기반의 오픈 소스 딥러닝 라이브러리로 주로 딥러닝 모델을 개발하고 학습하는 데 사용된다. 텐서플로우의 경쟁자라고 할 수 있는데 요새는 파이토치가 더 대세인 것 같다.
Torchvision : 토치비전은 파이토치의 공식 라이브러리로 컴퓨터 비전 작업을 위한 도구를 제공한다. 주요 기능으로는 여러 유명한 데이터셋을 쉽게 로드할 수 있는 도구를 제공하고 데이터 증강 및 변환을 위한 다양한 함수를 제공하며, 몇가지 유명한 사전 훈련된 딥러닝 모델을 제공하고 있다.
YOLOv5는 실시간 객체 감지를 위해 개발된 딥러닝 모델로, PyTorch 딥러닝 프레임워크를 사용하여 구현되었다. 따라서 YOLOv5를 사용하려면 PyTorch가 사전에 설치되어 있어야 하며, YOLOv5 모델의 정의, 학습, 평가, 추론 모든 과정에서 PyTorch의 API를 활용한다.
아래 사이트에서 JetPack 버전에 따라 설치해야할 PyTorch와 Torchvision 버전을 확인할 수 있다.
https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
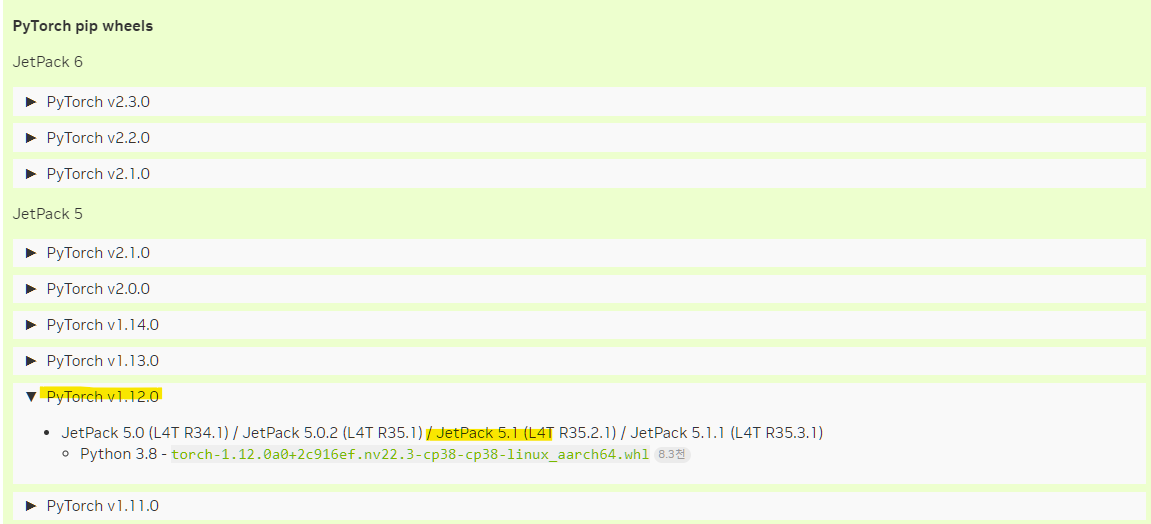
내 젯슨 보드에 설치된 JetPack은 v5.1.3으로 PyTorch v1.12.0을 먼저 설치한다.
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
그리고 다음 명령으로 PyTorch를 설치해주면 되는데 버전에 따른 URL과 file_name은 위 Jetson 포럼에서 확인할 수 있다.
wget <URL> -O <file_name>
pip3 install <file_name>
PyTorch v1.12.0의 경우 다음과 같다.
- file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
wget https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl -O torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
pip3 install torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whlpip3 install 'Cython<3'
그 다음 PyTorch 버전에 따른 torchvision 버전도 위 젯슨 포럼사이트에서 확인할 수 있다. 나의 경우 torchvision v0.13.0을 설치한다.

sudo apt install -y libjpeg-dev zlib1g-dev
자신이 설치할 버전에 맞게 버전넘버는 수정해주면 된다.
git clone --branch v0.13.0 https://github.com/pytorch/vision torchvision
cd torchvision
export BUILD_VERSION=0.13.0
python3 setup.py install --user
cd ../
설치 후 다음와 같이 설치가 잘 됐는지 verification할 수 있다.
>>> import torch
>>> print(torch.__version__)
>>> import torchvision
>>> print(torchvision.__version__)
>>> print('CUDA available: ' + str(torch.cuda.is_available()))
>>> print('cuDNN version: ' + str(torch.backends.cudnn.version()))

2. YOLOv5 저장소를 클론하고 종속성 설치하기
다음 레포를 클론하고 폴더로 이동한다.
git clone https://github.com/ultralytics/yolov5
cd yolov5/
다음 디펜던시를 설치한다.
sudo apt install -y libfreetype6-dev
그 다음 requirements.txt에 있는 필요한 패키지들을 설치해 줄텐데 PyTorch와 torchvision을 별도로 설치를 했으니 주석처리하든 지우든 하고 저장한다.
vim requirements.txt
필요한 패키지들을 설치한다.
pip3 install -r requirements.txt
yolov5 레포 폴더 안에다가 탐지할 객체가 포함된 YOLOv5 릴리즈 모델 파일을 다운로드 한다.
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
yolov5s.pt 파일은 모델의 구조와 사전 훈련된 가중치를 포함한 YOLOv5의 공식 배포 버전 중 하나인데 딥러닝 프레임워크로 PyTorch를 사용하기 때문에 확장자가 .pt이다.
YOLOv5의 공식 배포 버전은 뒤에 붙은 알파벳에 따라서 n, s, m, l, x 등 이 있고, 그 중에서 YOLOv5s.pt는 상대적으로 가볍고 빠른 모델이다.
다음 공식 레포에 있는 detect.py를 통해서 객체탐지를 수행할 수 있다.
detect.py 파일 상단에는 사용방법이 나와있다.
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
"""
Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
Usage - sources:
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
"""
이 스크립트는 다양한 입력 소스와 모델 형식을 명령줄 인수를 통해 설정하는 형태인데 입력 소스는 보면 알겠지만 웹캠, 이미지, 비디오, 이미지의 리스트, 유튜브 링크, 비디오 스트리밍 데이터 등 다양한 형식을 지원다.
USB 웹캠 소스 사용시 커맨드
$ python detect.py --weights yolov5s.pt --source 0
또는
$ python detect.py --weights yolov5s.pt --source 1

성은은 0.066ms(15fps) 정도 나온다.
YOLOv5는 COCO 데이터셋을 사용해 학습되어 사람, 자동차, 자전거, 개, 고양이 같은 다양한 일상적인 객체를 포함해 80개의 기본 클래스를 탐지할 수 있다. 만약 이 80개에 없는 내가 원하는 특정 객체를 탐지하게 하려면 직접 데이터셋을 준비하고 전이학습을 통해 추가훈련시키면 된다.
'임베디드 개발 > 젯슨' 카테고리의 다른 글
| Jetson ] USB over Internet (0) | 2025.01.19 |
|---|---|
| Jetson Xavier NX ] NoMachine으로 원격 제어하기 (0) | 2024.06.16 |
| Jetson Xavier NX 냉각 팬 프로파일 변경 (0) | 2024.06.10 |
| JetPack 5.x에 VSCode 설치 (0) | 2024.05.22 |
| Nvidia Jetson Xavier NX 보드에 SDK Manager로 JetPack 설치하기 (3) | 2024.05.22 |



