1. 파이썬의 특징
✓ 동적인 자료형 결정
데이터 타입은 변수에 값이 할당되는 시점에 동적으로 결정된다.
a = 1
b = 1.0
c = 'hello'
print(type(a))
print(type(b))
print(type(c))
✓ 자동 메모리 관리
개발자가 직접 메모리를 관리할 필요 없고, 자료형의 범위 또한 필요에 따라 자동으로 확장되기 때문에 일반적으로 고려할 필요 없다.
✓ 체이닝
체이닝은 메서드나 연산자를 연속적으로 연결해서 한 줄로 작성하는 방식을 말한다.
특히 메서드 체이닝은 각 메서드가 객체 자기 자신(self) 또는 새로운 객체를 반환해야 가능한 방식인데, 파이썬에서 빈번하게 사용되는 패턴 중 하나다.
# strip() 함수는 공백을 제거하거나 특정 문자 또는 문자열을 제거함
result = " Hello, World! ".strip().lower().replace("hello", "hi").strip('!')
print(result)# 논리 연산자 체이닝
age = 25
result = 18 <= age <= 30 # 18과 30 사이인지 확인
print(result) # True
✓ 들여쓰기 (공백 4칸)
파이썬에서 들여쓰기란 코드의 블록을 정의하고, 프로그램의 흐름을 제어하는 핵심 문법이다. 다른 언어와 달리 중괄호가 없으므로 들여쓰기 수준이 곧 코드의 구조와 실행 범위를 의미한다.
for i in range(3):
print("loop:", i)
for j in range(2):
print("internal loop:", j)
✓ 주석 (#)
파이썬에서 주석을 작성할 땐 # 기호를 사용한다. 여러 줄 주석 문법은 공식적으로 존재하지 않지만, 세 개의 따옴표로 감싸는 문서 문자열(docstring)이 특정 위치에서 여러 줄 주석처럼 활용되기도 한다.
# 한 줄 주석
"""
이 모듈에 대한 설명
"""
import math
def add(a, b):
"""두 수를 더하는 함수"""
return a + b
class MyClass:
"""
클래스에 대한 설명
"""
2. 파이썬의 기본 자료형 및 관련 함수
2.1. 숫자 자료형 및 관련 함수
✓ 숫자 자료형 : 정수형 int, 실수형 float, 복소수형 complex
a = 1
b = 1.2
c = 1 + 2j
print(type(a))
print(type(b))
print(type(c))
✓ 2진수 표현 (0b)
a = 0b101
print(a)
print(type(a))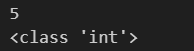
✓ 16진수 표현 (0x)
a = 0x400
print(a)
print(type(a))
✓ 10진수 정수를 2진수 문자열 또는 16진수 문자열로 변환 : bin(), hex()
# 10진수 정의
decimal = 42
# 10진수를 2진수 문자열로 변환
binary = bin(decimal)
print(f"{decimal}의 2진수 표현: {binary}")
# 10진수를 16진수 문자열로 변환
hexadecimal = hex(decimal)
print(f"{decimal}의 16진수 표현: {hexadecimal}")

✓ 10진수 정수를 문자열로 변환 : str()
n = 42
s = str(n)
print(s) # '42'
print(type(s)) # <class 'str'>
✓ 문자열을 정수로 변환 : int()
print(int('0b101010', 2)) # 42
print(int('0x2a', 16)) # 42
print(int('42')) # 42
✓ 산술 연산자
x = 10
y = 3
print(x + y) # 13
print(x - y) # 7
print(x * y) # 30
print(x / y) # 3.3333333333333335
print(x // y) # 정수 나눗셈 3
print(x % y) # 나머지 1
print(x ** y) # 거듭제곱 1000
※ 파이썬에는 증감연산자가 없다.
대신 +=, -= 연산자를 사용한다.
counter += 1
counter -= 1
✓ 비교 연산자
x = 5
y = 10
print(x == y) # False
print(x != y) # True
print(x > y) # False
print(x < y) # True
print(x >= 5) # True
print(x <= 10) # True
✓ 논리 연산자
a = True
b = False
print(a and b) # False
print(a or b) # True
print(not a) # False
✓ 삼항 연산자
"(True일 때 값) if (Condition) else (False일 때 값)" 형식을 사용한다.
# 예시 1: 숫자 비교
a = 10
b = 20
min_value = a if a < b else b
print(min_value) # 출력: 10
# 예시 2: 문자열
status = "success" if a + b == 30 else "failure"
print(status) # 출력: success
# 예시 3: 리스트 요소 처리
numbers = [1, 2, 3, 4]
item = numbers[0] if numbers else None
print(item) # 출력: 1
※ 시퀀스 ⊂ 컬렉션 ⊂ 컨테이너
- 컨테이너(Container) : 다른 객체들을 내부에 담고, x in y 문법으로 포함 여부를 검사할 수 있는 자료
- 컬렉션(Collection) : 여러 데이터를 하나의 객체로 묶어 관리하는 자료형의 총칭
- 시퀀스(Sequence) : 요소에 순서가 있고, 인덱싱과 슬리이싱이 가능한 자료형
- 시퀀스 자료형 : list, tuple, str, range
- 컬렉션이지만 시퀀스가 아닌 자료형 : set, dict
2.2. string 자료형 및 관련 함수
파이썬에서 문자열을 만들 때는 큰따옴표 " 또는 작은 따옴표 ' 를 사용할 수 있다. 또한 문자열은 불변(immutable) 타입이기 때문에 한번 생성된 문자열의 내용을 직접 변경할 수 없으며, 대신 문자열을 조작해 새로운 문자열을 만드는 것은 가능하다.
s = "Hello, World!"
s = 'Hello, World!'
s[0] = "H" # Not OK ❌
s = "H" + s[1:] # OK ⭕
✓ 문자열 연산
문자열에 + 또는 * 연산을 사용할 수 있다.
# 문자열 연결
s1 = "Hello"
s2 = "World"
print(s1 + ", " + s2 + "!") # Hello, World!
# 문자열 반복
s3 = "abc"
print(s3 * 3) # abcabcabc
✓ 문자열 인덱싱 및 슬라이싱
문자열의 각 문자는 0부터 시작하는 인덱스를 가지며, 이를 통해 특정 위치의 문자에 접근할 수 있고, 슬라이싱 기능을 사용하면 문자열의 일부분을 손쉽게 추출할 수 있다.
# 인덱싱
s = "Hello, World!"
print(s[0]) # H
print(s[-1]) # !
# 슬라이싱
print(s[0:5]) # Hello
print(s[7:]) # World!
참고로 [시작인덱스:종료인덱스] 형태의 슬라이싱에서 범위는 시작 인덱스부터 종료 인덱스 바로 앞까지이다. 즉, 종료 인덱스는 포함되지 않는다. 예를 들어 [0:5]는 0번째 인덱스부터 4번째 인덱스까지의 문자를 추출한다.
또한 문자열의 처음이나 끝을 기준으로 슬라이싱할 경우 인덱스를 생략할 수 있다. 예를 들어 [:5]는 처음부터 4번째 인덱스까지, [7:]는 7번째 인덱스부터 문자열 끝까지를 의미한다.
문자열을 뒤에서부터 접근할 때는 음수 인덱스를 사용하며, [-1]은 문자열의 마지막 문자를 의미한다.
✓ 주요 문자열 함수
- upper(), lower(): 문자열을 대문자로 또는 소문자로 변환한다.
- strip(): 문자열 양쪽 끝의 공백 또는 지정한 문자들을 제거한다.
- replace(old, new): 문자열 내의 특정 문자나 문자열을 다른 문자열로 교체한다.
- find(sub): 특정 부분 문자열이 위치한 첫 인덱스를 반환하고, 없으면 -1을 반환한다.
s = " Hello, World! "
print(s.upper()) # HELLO, WORLD!
print(s.lower()) # hello, world!
print(s.strip()) # Hello, World!
print(s.replace("l", "L")) # HeLLo, WorLd!
print(s.find("Wor")) # 8
print(s.find("?")) # -1
2.3. list 자료형 및 관련 함수
리스트는 대괄호([])를 사용해 생성하며, 각 요소는 쉼표로 구분된다. 또한 리스트에는 서로 다른 데이터 타입의 요소를 함께 포함할 수 있다.
my_list = [1, 2, 3, 4, 5]
names = ["Alice", "Bob", "Charlie"]
mixed_list = [1, "Alice", True, 2.34]
✓ 리스트 연산
list1 = [1, 2, 3]
list2 = [4, 5, 6]
# 리스트 연결
combined_list = list1 + list2
print(combined_list) # [1, 2, 3, 4, 5, 6]
# 리스트 반복
repeated_list = list1 * 3
print(repeated_list) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
✓ 리스트 인덱싱 및 슬라이싱
my_list = [1, 2, 3, 4, 5]
# 인덱싱
print(my_list[0]) # 1
print(my_list[-1]) # 5 (리스트의 마지막 요소)
# 슬라이싱
print(my_list[1:4]) # [2, 3, 4]
✓ 리스트 요소 수정 및 삭제
my_list = [1, 2, 3, 4, 5]
# 요소 수정
my_list[0] = 10
print(my_list) # [10, 2, 3, 4, 5]
# 연속된 범위의 요소 수정
my_list[:2] = [9, 8]
print(my_list) # [9, 8, 3, 4, 5]
# del로 요소 삭제
del my_list[0]
print(my_list) # [8, 3, 4, 5]
# []로 요소 삭제
my_list[2:] = []
print(my_list) # [8, 3]
✓ 주요 리스트 함수
- append(): 리스트의 끝에 새로운 요소를 추가한다.
- extend(): 리스트에 다른 리스트(또는 다른 컬렉션)의 모든 요소를 추가한다.
- insert(): 지정된 인덱스에 요소를 삽입한다.
- remove(): 리스트에서 첫 번째로 나타나는 특정 값을 제거한다. 특정 값이 없는 경우 ValueError를 발생시킨다.
- pop(): 특정 인덱스의 요소를 제거하고, 그 요소를 반환한다. 인덱스를 지정하지 않으면, 마지막 요소를 제거하고 반환한다.
- clear(): 리스트의 모든 요소를 제거한다.
fruits = ['apple', 'banana']
fruits.append('cherry')
print(fruits) # ['apple', 'banana', 'cherry']
fruits.extend(['date', 'elderberry'])
print(fruits) # ['apple', 'banana', 'cherry', 'date', 'elderberry']
fruits.insert(1, 'blueberry')
print(fruits) # ['apple', 'blueberry', 'banana', 'cherry', 'date', 'elderberry']
fruits.remove('banana')
print(fruits) # ['apple', 'blueberry', 'cherry', 'date', 'elderberry']
fruit = fruits.pop()
print(fruit) # 'elderberry'
print(fruits) # ['apple', 'blueberry', 'cherry', 'date']
fruits.clear()
print(fruits) # []
- index(): 리스트에서 특정 값이 처음 나타나는 인덱스를 반환한다. 두번째, 세번째 인자로 검색 범위를 지정할 수 있고 찾고자 하는 값이 없는 경우 ValueError를 발생시키기 때문에 예외처리가 필요하다.
- count(): 리스트에서 특정 값이 나타나는 횟수를 반환한다.
- reverse(): 리스트의 요소 순서를 뒤집는다.
- copy(): 리스트의 얕은 복사본을 새로운 리스트로 반환한다.
- sort(): 리스트의 요소를 정렬한다. key 매개변수를 통해 정렬 기준을 지정하고, reverse 매개변수로 내림차순 정렬을 지정할 수 있다.
numbers = [1, 2, 3, 4, 3, 2, 1]
try:
index_position = my_list.index(3)
print("First value 3 is at index:", index_position) # First value 3 is at index: 2
except ValueError:
print("The value is not in the list.")
print(numbers.index(3, 3)) # 4, 인덱스 3부터 끝까지 3을 찾음
print(numbers.count(3)) # 2
numbers.reverse()
print(numbers) # [1, 2, 3, 4, 3, 2, 1]
numbers_copy = numbers.copy()
print(numbers_copy) # [1, 2, 3, 4, 3, 2, 1]
numbers.sort()
print(numbers) # [1, 1, 2, 2, 3, 3, 4]
numbers.sort(reverse=True)
print(numbers) # [4, 3, 3, 2, 2, 1, 1]
words = ["banana", "apple", "cherry", "date"]
words.sort(key=len) # 문자열의 길이에 따라 정렬
print(words) # ['date', 'apple', 'banana', 'cherry']
tuples = [(1, 'banana'), (2, 'apple'), (3, 'cherry'), (4, 'date')]
tuples.sort(key=lambda x: x[1]) # 튜플로 구성된 리스트에서 각 튜플의 두 번째 요소에 따라 정렬
print(tuples) # [(2, 'apple'), (1, 'banana'), (3, 'cherry'), (4, 'date')]
※ 리스트 자료형을 통해 참조와 얕은 복사, 깊은 복사의 차이 알아보기
파이썬에서 리스트를 다른 변수에 대입 연산자(=) 로 할당하면, 새로운 리스트가 생성되는 것이 아니라 같은 리스트 객체를 가리키는 참조(reference)가 전달된다.
즉, 아래 예시에서 listA와 listB는 서로 다른 변수가 아니라 같은 리스트 객체를 참조한다. 따라서 listB를 통해 리스트를 수정하면, listA에서도 그 변경이 그대로 반영된다.
listA = [1, 2, 3, 4]
listB = listA
listB[0] = 99
print(listA) # 출력: [99, 2, 3, 4]
print(listB) # 출력: [99, 2, 3, 4]
리스트의 얕은 복사(shallow copy)는 copy 모듈의 copy() 함수나 슬라이싱([:])을 사용해 수행할 수 있다.
얕은 복사는 리스트 객체 자체는 새로 생성하지만, 리스트 안에 들어 있는 요소들은 원본 리스트의 요소들을 그대로 참조한다. 즉, 객체의 첫 번째 수준만 복사된다.
# copy를 사용한 얕은 복사
import copy
listA = [1, 2, 3, 4]
listB = copy.copy(listA)# 슬라이싱을 사용한 얕은 복사
listA = [1, 2, 3, 4]
listB = listA[:]
listB[0] = 99
print(listA) # 출력: [1, 2, 3, 4]
print(listB) # 출력: [99, 2, 3, 4]
위 예시처럼 리스트의 첫 번째 수준 요소가 정수형과 같은 불변(immutable) 객체라면, 얕은 복사를 사용해도 두 리스트는 서로 독립적으로 동작한다.
하지만 리스트의 요소가 또 다른 리스트처럼 가변(mutable) 객체인 경우에는 주의가 필요하다.
아래 예시에서는 리스트를 얕은 복사했지만, 내부 리스트는 여전히 같은 객체를 참조하고 있기 때문에 한쪽의 변경이 다른 쪽에도 영향을 미친다. 즉, 얕은 복사는 컨테이너만 새로 만들고, 내부 요소는 공유한다는 점이 핵심이다.
listA = [[1, 2], [3, 4]]
listB = listA[:]
listB[0][0] = 99
print(listA) # 출력: [[99, 2], [3, 4]]
print(listB) # 출력: [[99, 2], [3, 4]]
한 편, 리스트의 깊은 복사(deep copy)는 copy 모듈의 deepcopy() 함수를 사용해 수행할 수 있다.
깊은 복사는 리스트뿐만 아니라, 리스트 내부에 포함된 모든 요소를 재귀적으로 복사하여 완전히 독립적인 객체 구조를 생성한다.
아래 예시처럼 깊은 복사를 사용하면, 한 리스트의 변경이 다른 리스트에 전혀 영향을 미치지 않는다.
import copy
listA = [[1, 2], [3, 4]]
listB = copy.deepcopy(listA)
listB[0][0] = 99
print(listA) # 출력: [[1, 2], [3, 4]]
print(listB) # 출력: [[99, 2], [3, 4]]
※ 컨테이너가 비어 있는지 확인하는 법
파이썬에서 시퀀스나 컬렉션과 같은 컨테이너가 비어 있는지 확인할 때는 len() 함수를 호출하는 것보다, 해당 컨테이너를 직접 불리언 컨텍스트에서 평가하는 방법을 권장한다.
비어 있는 컨테이너는 False로 평가되고, 요소가 하나라도 존재하면 True로 평가된다.
my_list = []
if not my_list:
print("리스트가 비어 있습니다.")
else:
print("리스트에 데이터가 있습니다.")
2.4. bytearray 자료형
bytearray는 바이트 단위의 데이터를 효율적으로 저장하고 처리하기 위해 설계된 시퀀스 자료형이다. str이나 bytes와 달리, 생성 후에도 길이와 내용을 변경할 수 있는 가변(mutable)한 바이트 배열을 제공한다. 이러한 특징으로 인해 네트워크 통신이나 파일 입출력에서 바이트 단위의 데이터 조작이 필요한 경우에 주로 사용한다.
각 요소는 0부터 255 사이의 정수 값으로 표현되며, 인덱싱과 슬라이싱을 지원한다.
# bytearray 생성
ba = bytearray([0x0f, 0x01, 0x02])
# 문자열과 인코딩 지정하여 생성
ba1 = bytearray("hello", "utf-8")
# bytearray 요소 접근 및 수정
print(ba[0]) # 15
ba[1] = 0xFF # 두 번째 요소를 255로 변경
print(ba) # bytearray(b'\x0f\xff\x02')
# bytearray에 요소 추가
ba.append(0x03)
print(ba) # bytearray(b'\x0f\xff\x02\x03')
2.5. tuple 자료형 (+ 리스트와의 차이)
튜플(tuple)은 리스트와 유사하지만, 불변(immutable) 자료형으로 한 번 생성되면 그 내용을 변경할 수 없다. 이러한 불변성 때문에 프로그램에서 데이터가 변경되지 않아야 하는 경우에 튜플을 사용하는 것이 적합하다.
대표적인 예로, 함수에서 여러 값을 반환할 때 파이썬은 기본적으로 반환 값을 튜플로 패킹하여 전달한다.
튜플은 쉼표(,)로 구분된 여러 값을 소괄호()로 감싸서 생성하며, 경우에 따라 소괄호를 생략할 수도 있다.
my_tuple = (1, 2, 3)
print(my_tuple) # 출력: (1, 2, 3)
# 괄호 없이 튜플 생성
another_tuple = 4, 5, 6
print(another_tuple) # 출력: (4, 5, 6)
# 한 개 요소만 갖는 튜플
single_element_tuple = (7,)
print(single_element_tuple) # 출력: (7,)
✓ 튜플의 인덱싱과 슬라이싱
튜플은 리스트와 동일한 방식으로 요소에 접근해 조회할 수 있지만, 내용을 수정할 수는 없다.
t = (0, 1, 2, 3, 4, 5)
# 인덱싱
print(t[0]) # 출력: 0
print(t[-1]) # 출력: 5
# 슬라이싱
print(t[1:4]) # 출력: (1, 2, 3)
2.6. dictionary 자료형
딕셔너리(dict)는 키(key)와 값(value)의 쌍으로 데이터를 저장하는 자료형이다. 키는 딕셔너리 내에서 유일해야 하며 불변(immutable)한 값만 사용할 수 있고, 값은 해당 키에 대응하는 데이터를 저장하는 데 사용된다.
딕셔너리는 중괄호{}를 사용해 생성하며, 각 키-값 쌍은 쉼표로 구분하고, 키와 값은 콜론(:)으로 연결한다.
{키1:밸류1, 키2:밸류2}
# 딕셔너리 생성
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
print(my_dict) # 출력: {'name': 'John', 'age': 30, 'city': 'New York'}
# 빈 딕셔너리 생성
empty_dict = {}
print(empty_dict) # 출력: {}
✓ 딕셔너리 데이터에 접근, 수정 및 삭제
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# 값 접근
print(my_dict['name']) # 출력: John
# 값 추가
my_dict['email'] = 'john@example.com'
print(my_dict) # 출력: {'name': 'John', 'age': 30, 'city': 'New York', 'email': 'john@example.com'}
# 값 수정
my_dict['age'] = 35
print(my_dict) # 출력: {'name': 'John', 'age': 35, 'city': 'New York', 'email': 'john@example.com'}
# 값 삭제
del my_dict['city']
print(my_dict) # 출력: {'name': 'John', 'age': 35, 'email': 'john@example.com'}
✓ 딕셔너리의 주요 함수
- get(): 키로 값을 조회하되, 키가 없는 경우 None 또는 지정된 기본 값을 반환한다.
- update(): 다른 딕셔너리의 키-값 쌍을 현재 딕셔너리로 복사하여 추가하거나 업데이트한다
- keys(): 딕셔너리의 모든 키를 반환한다.
- values(): 딕셔너리의 모든 값을 반환한다.
- items(): 딕셔너리의 모든 키-값 쌍을 튜플로 반환한다.
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
print(my_dict.get('name')) # 출력: John
print(my_dict.get('location', 'Not Found')) # 출력: Not Found
my_dict.update({'age': 32, 'city': 'Boston'})
print(my_dict) # 출력: {'name': 'John', 'age': 32, 'email': 'john@example.com', 'city': 'Boston'}
print(my_dict.keys()) # 출력: dict_keys(['name', 'age', 'city'])
print(list(my_dict.values())) # 출력: ['John', 32, 'john@example.com', 'Boston']
for key, value in my_dict.items():
print(f"{key}: {value}")
2.7. set 자료형
파이썬에서 set은 중복을 허용하지 않고 순서가 없는 컬렉션이다. set은 중괄호{}를 사용해 생성하거나, set() 함수를 통해 다른 시퀀스를 집합으로 변환하여 만들 수 있다.
set은 요소의 유일성을 보장하고 순서를 유지하지 않는 특성 때문에, 주로 요소의 존재 여부를 확인하거나 중복 데이터를 제거하는 용도로 사용된다.
# 세트 생성
my_set = {1, 2, 3, 4, 5}
print(my_set) # 출력: {1, 2, 3, 4, 5}
# 빈 세트 생성
empty_set = set()
print(empty_set) # 출력: set()
# 리스트에서 세트로 변환 (중복 제거)
my_list = [1, 2, 2, 3, 4, 4, 4, 5]
unique_set = set(my_list)
print(unique_set) # 출력: {1, 2, 3, 4, 5}
✓ set의 집합 연산
set는 수학적 집합 연산을 지원한다. 여기에는 합집합, 교집합, 차집합, 대칭 차집합 등이 포함된다.
a = {1, 2, 3, 4}
b = {3, 4, 5, 6}
# 합집합
print(a | b) # 출력: {1, 2, 3, 4, 5, 6}
# 교집합
print(a & b) # 출력: {3, 4}
# 차집합
print(a - b) # 출력: {1, 2}
# 대칭 차집합 (XOR)
print(a ^ b) # 출력: {1, 2, 5, 6}
✓ set의 주요 함수
- add(): 세트에 요소를 추가한다.
- remove(): 세트에서 요소를 제거한다. 요소가 세트에 없으면 KeyError를 발생시킨다.
- discard(): 세트에서 요소를 제거한다. 요소가 세트에 없어도 에러가 발생하지 않는다.
- clear(): 세트의 모든 요소를 제거한다.
- update(): 여러 요소를 한 번에 추가한다. |= 연산자(합집합)와 유사하다.
my_set = {1, 2, 3, 4, 5}
my_set.add(6)
print(my_set) # 출력: {1, 2, 3, 4, 5, 6}
my_set.remove(6)
print(my_set) # 출력: {1, 2, 3, 4, 5}
my_set.discard(10) # 에러 발생하지 않음
my_set.clear()
print(my_set) # 출력: set()
my_set.update([1, 2, 7, 8])
print(my_set) # 출력: {1, 2, 7, 8}
3. 제어문 및 반복문
✓ if, elif, else 제어문
파이썬에서 제어문의 기본 구조는 다음과 같다. 조건문에는 비교 연산자나 and, or, not 같은 논리 연산자가 함께 사용되는 경우가 많다.
if 조건문:
# do something
elif 조건문:
# do something
else:
# do something
age = 20
if age < 18:
print("미성년자입니다.")
elif age >= 18 and age < 65:
print("성인입니다.")
else:
print("노인입니다.")
✓ while 반복문
while 조건문:
# do somthingcount = 0
while count < 5:
print(f"카운트: {count}")
count += 1
while True:
# do something
✓ 반복문에서 break와 continue
다른 언어와 마찬가지로, 조건에 따라 break와 continue 문을 사용해 반복 흐름을 제어할 수 있다.
for num in range(10):
if num == 5:
break # 숫자 5에서 반복문을 종료합니다.
if num % 2 == 0:
continue # 짝수는 출력하지 않고 반복문의 다음 순회로 진행합니다.
print(f"현재 숫자: {num}")
✓ for 반복문
for 반복문은 리스트, 튜플, 문자열과 같은 시퀀스 자료형과, 반복 가능한(iterable) 객체를 순회하며 반복 작업을 수행하는 데 사용된다.
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(f"현재 과일: {fruit}")
# 딕셔너리의 키와 값에 접근
pets = {'dog': 'bark', 'cat': 'meow', 'bird': 'tweet'}
for animal, sound in pets.items():
print(f"The {animal} goes {sound}")
✓ for 반복문과 range() 함수
range() 함수는 연속된 정수 범위를 표현하는 이터러블 객체를 반환하며, for 반복문과 함께 자주 사용된다. (실제 값들은 미리 생성되지 않고 반복 과정에서 하나씩 생성된다.)
- 기본 사용법 : range(end) : 0 부터 end - 1 까지의 정수를 생성한다.
- 시작과 끝 지정 : range(start, end) : start 부터 end - 1 까지의 정수를 생성한다.
- 단계 추가 : range(start, end, step) : start 부터 step 만큼 증가하며 end -1 까지의 정수를 생성한다.
# 0부터 9까지 출력
for i in range(10):
print(i, end=' ') # 0 1 2 3 4 5 6 7 8 9
# 5부터 9까지 출력
for i in range(5, 10):
print(i, end=' ') # 5 6 7 8 9
# 0부터 9까지 2씩 증가하며 출력
for i in range(0, 10, 2):
print(i, end=' ') # 0 2 4 6 8
✓ 리스트 컴프리헨션(list comprehension)
리스트 컴프리헨션은 리스트 내부에 for 문을 포함시켜 새로운 리스트를 간결하게 생성하는 문법이다.
[표현식 for 항목 in iterable객체 if 조건]# 0부터 9까지의 숫자를 포함하는 리스트를 생성
numbers = [x for x in range(10)]
print(numbers) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 각 숫자의 제곱을 리스트로 생성
squares = [x**2 for x in range(10)]
print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 기존 리스트를 사용해 2의 거듭제곱을 리스트로 생성
a = [0, 1, 2, 3, 4]
b = [2**i for i in a]
print(b) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 기존 리스트를 사용해 홀수인 경우만 2의 거듭제곱을 리스트로 생성
c = [2**i for i in a if i % 2 != 0]
print(c) # [2, 8]
리스트 컴프리헨션에서 for 문의 반복 변수를 표현식에서 사용하지 않는 경우, 관례적으로 _를 사용해 해당 값이 의미 없음을 표현할 수 있다.
# 길이가 10인 리스트를 모두 0으로 초기화
list1 = [0 for _ in range(10)]
# 길이가 100인 리스트를 모두 ''로 초기화
list2 = ['' for _ in range(100)]
✓ 2차원 리스트 컴프리헨션
기본 구조와 사용예시는 다음과 같다.
[[표현식 for 항목 in 반복가능객체] for 항목 in 반복가능객체]# 모든 요소를 ''로 초기화한 2x3 행렬 생성
matrix = [['' for _ in range(3)] for _ in range(2)]
for row in matrix:
print(row)
['', '', '']
['', '', '']# 요소가 행*열 길이+열인 3x5 행렬 생성
matrix = [[5 * y + x for x in range(5)] for y in range(3)]
for row in matrix:
print(row)
[0, 1, 2, 3, 4]
[5, 6, 7, 8, 9]
[10, 11, 12, 13, 14]
4. 예외 처리 (Exception Handling)
프로그램 실행 중 발생할 수 있는 오류 상황을 예외(Exception) 라고 하며, try / except 구문을 사용해 이러한 예외를 처리할 수 있다.
예외 처리의 목적은 프로그램이 비정상적으로 종료되는 것을 방지하고, 오류 상황에 대한 대안을 구현하는 것이다.
✓ try / except 기본 구조
- try 블록 : 예외가 발생할 가능성이 있는 코드 작성
- except [예외타입] 블록 : 예외가 발생했을 때 실행할 코드를 작성
- else 블록 : 예외가 발생하지 않았을 때만 실행할 코드를 작성 (정상 흐름과 예외 흐름을 명확히 분리할 때)
- finally 블록 : 예외 발생 여부와 상관없이 항상 실행할 코드를 작성 (파일 닫기, 자원 해제 같은 정리작업에 사용)
try:
# 예외 발생 가능 코드
except 예외타입1:
# 특정 예외 처리
except 예외타입2:
# 또 다른 예외 처리
except:
# 모든 예외 처리 (비권장, 가급적 예외 타입 명시)
else:
# 예외가 발생하지 않았을 때만 실행
finally:
# 예외 발생 여부와 상관없이 항상 실행
예시.
try:
x = int("abc")
except ValueError:
print("정수로 변환할 수 없습니다.")
대표적인 예외들.
ValueError # 타입은 맞지만 값의 의미가 올바르지 않을 때 발생
TypeError # 연산이나 함수 호출에 사용된 객체의 타입이 맞지 않을 때 발생
ZeroDivisionError # 0으로 나누기 연산을 수행했을 때 발생
OverflowError # 숫자가 표현 가능한 범위를 초과했을 때 발생
IndexError # 시퀀스(list, tuple 등)의 인덱스 범위를 벗어났을 때 발생
KeyError # 딕셔너리에 존재하지 않는 키에 접근했을 때 발생
FileNotFoundError # 지정한 경로의 파일이 존재하지 않을 때 발생
PermissionError # 파일이나 자원에 대한 접근 권한이 없을 때 발생
IsADirectoryError # 파일을 기대했지만 디렉터리를 대상으로 작업했을 때 발생
IOError # 입출력(I/O) 작업 중 일반적인 오류가 발생했을 때 (Python3에선 OSError의 alias)
ImportError # import 대상이 존재하지만 로딩에 실패했을 때 발생
ModuleNotFoundError # import하려는 모듈 자체가 존재하지 않을 때 발생
StopIteration # iterator가 더 이상 반환할 값이 없음을 알릴 때 발생
AttributeError # 객체에 존재하지 않는 속성(attribute)에 접근했을 때 발생
NameError # 정의되지 않은 변수나 이름을 참조했을 때 발생
※ 예외 처리 시 권장되는 설계 원칙
예외는 조건 분기의 대체제가 아니라, 프로그램이 정상적으로 진행될 수 없는 비정상 흐름을 표현하고 제어하기 위한 수단으로 쓰여야 한다. 예외를 남발하면 실행 비용이 증가하고 코드의 가독성이 저하되므로, 필요한 경우에만 사용하는 것이 바람직하다.
또한 예외 처리는 실제로 복구하거나 대응이 가능한 예외만 명시적으로 잡아서 처리하고, 처리할 수 없는 예외는 상위 호출자로 전파되도록 두는 것이 좋다. 의미 없이 모든 예외를 Exception으로 잡아 처리하는 방식은 지양해야 한다.
✓ 예외 직접 발생시키기 & 예외 객체 받기
raise 키워드를 사용하면 의도적으로 예외를 발생시킬 수 있고, except 블록에서는 as 키워드를 통해 예외 객체를 받아 처리할 수 있다. 이때 예외 객체를 print()로 출력하면, 해당 예외에 정의된 메시지가 출력된다.
또한 Exception을 상속한 클래스로 직접 예외 클래스를 정의할 수도 있다.
class MyError(Exception):
pass
def divide(a, b):
if b == 0:
raise MyError("0으로 나눌 수 없습니다.")
return a / b
try:
divide(10, 0)
except MyError as e:
print("에러 메시지:", e)
5. 파이썬의 사용자 정의 함수
파이썬에서 함수는 def 키워드를 사용해 정의된다. 함수는 이름과 괄호 안에 쉼표로 구분된 매개변수 목록, 그리고 콜론(:)으로 끝나는 헤더로 구성된다. 함수의 본문은 다음 줄에서 들여쓰기를 하고 작성한다.
def function_name(parameters):
# 함수 본문
return value
def add(a, b):
return a + b
result = add(5, 3)
print(result) # 출력: 8
✓ 여러 값을 반환하는 함수와 반환값 무시
함수가 반환한 여러 값 중 필요 없는 값은 _로 받아 명시적으로 무시할 수 있다. 이는 코드의 의도를 분명하게 드러내는 파이썬의 관례이다.
def stats(numbers):
return max(numbers), min(numbers), sum(numbers) / len(numbers)
maximum, minimum, average = stats([1, 2, 3, 4, 5])
print(maximum, minimum, average) # 출력: 5 1 3.0
_, _, average = stats([10, 20, 30, 40, 50])
print(average) # 출력: 30.0
6. 변수의 스코프와 변수 조작 방법
✓ 지역변수와 전역변수
지역변수는 함수 내부에서 정의되며, 해당 함수의 스코프(scope) 내에서만 사용할 수 있다. 반면 전역변수는 함수 외부에서 정의되고 프로그램 전체에서 접근할 수 있다.
def my_function():
local_var = 10
print(local_var) # 출력: 10
my_function()
# print(local_var) # NameError: name 'local_var' is not definedglobal_var = 20
def my_function():
print(global_var) # 출력: 20
my_function()
print(global_var) # 출력: 20
✓ static 지역 변수 ❌, global 키워드로 함수 내에서 전역 변수 조작하기
파이썬에는 C/C++과 같은 static 지역 변수 개념이 존재하지 않는다. 즉, 함수 안에서 정의되었지만 전역 변수처럼 생명주기가 유지되는 변수는 없다.
한편, 함수 내부에서 전역 변수를 수정하려면 해당 변수 앞에 global 키워드를 명시해야 한다. global 키워드를 사용하지 않으면, 같은 이름의 변수가 전역 범위에 존재하더라도 함수 내부에서는 새로운 지역 변수로 취급된다.
global_var = 30
def my_function():
global global_var
global_var = 40
print(global_var) # 출력: 40
my_function()
print(global_var) # 출력: 40
✓ 제어문 내부에서 선언된 지역 변수의 사용
파이썬에서 지역 변수의 스코프는 함수 단위로 적용된다. 따라서 함수 내부의 조건문(if)이나 반복문(for, while) 안에서 선언된 변수도 모두 해당 함수의 지역 변수로 간주된다.
이로 인해 제어문 내부에서 정의된 변수는, 같은 함수 안이라면 제어문 바깥에서도 사용할 수 있다. 단, 조건문이나 반복문이 실행되지 않은 경우, 해당 변수는 생성되지 않을 수 있으니 주의해야 한다.
def example_with_if(condition):
if condition:
inner_var = "I am inside if"
else:
inner_var = "I am inside else"
print(inner_var)
7. 주요 내장 함수
✓ print() 함수
표준출력장치에 지정된 값을 출력하는 함수이다.
print("Hello, world!")
- print(): 콤마 , 로 구분 출력
콤마 ,로 구분된 여러 값을 출력할 수 있으며, 각 값은 기본적으로 공백으로 구분되어 출력다.
a = "Hello"
b = "World"
print(a, b) # 출력: Hello World
- print(): 구분자 지정
sep 파라미터를 사용해 출력되는 값들 사이의 구분자를 지정할 수 있다.
print(a, b, sep=", ") # 출력: Hello, World
- print(): 라인 종료 문자 변경
기본적으로 print()는 출력 후에 줄바꿈을 수행하는데 end 파라미터를 사용하여 이 동작을 변경할 수 있다.
print("Hello", end=" ")
print("World") # 출력: Hello World
- print(): f-string (Formatted String Literals)
f-string은 Python 3.6 이상에서 도입된 문자열 포매팅 문법으로, f-string을 사용하면 기존 % 포매팅이나 str.format() 방식보다 간격하고 직관적으로 변수 값을 출력할 수 있다. 문자열 앞에 f를 붙이고, 중괄호{} 안에 변수나 콜론:과 표현식을 넣어 사용한다.
name = "John"
age = 30
print(f"{name} is {age} years old.") # 출력: John is 30 years old.
- print(): f-string을 사용해 특정 소숫점 자리 이하까지 표시하거나 특정 폭으로 정렬하기
number = 3.14159
print(f"{number:.2f}") # 출력: 3.14
# 중앙 정렬(^), 좌측 정렬(<), 우측 정렬(>) 사용 예
print(f"{name:^10}") # 출력: John
print(f"{name:<10}") # 출력: John
print(f"{name:>10}") # 출력: John
✓ 기타 주요 내장 함수
- len()
입력받은 컬렉션(ex: 문자열, 리스트, 튜플, 딕셔너리)의 요소 개수를 반환한다.
my_list = [1, 2, 3, 4]
print(len(my_list)) # 출력: 4
- type()
입력 값의 데이터 타입 반환한다.
print(type(123)) # 출력: <class 'int'>
print(type("Hello")) # 출력: <class 'str'>
- range()
지정된 범위의 숫자를 포함하는 시퀀스(iterable) 객체를 반환한다.
for i in range(5):
print(i) # 출력: 0 1 2 3 4
- int(), float(), str()
각각 정수, 부동소수점 숫자, 문자열로 타입 변환을 수행다.
print(int("10") + 5) # 출력: 15
print(float("10.5") + 0.5) # 출력: 11.0
print(str(20) + " years old") # 출력: 20 years old
- input()
사용자로부터 입력을 받아 문자열로 반환한다. 인자로 사용자 입력을 받기 전 출력 문구를 지정할 수 있다.
name = input("Enter your name: ")
print("Hello", name)
- sort(iterable)
입력받은 이터러블의 모든 항목을 정렬하여 새 리스트로 반환한다.
numbers = [5, 2, 9, 1]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 출력: [1, 2, 5, 9]
- max(iterable), min(iterable)
컬렉션 또는 개별인자들의 최대값 또는 최소값을 반환한다.
numbers = [5, 2, 9, 1]
print(max(numbers)) # 출력: 9
print(min(numbers)) # 출력: 1
print(max(3, 5, 1, 6)) # 출력: 6
- sum(iterable)
이터러블의 모든 항목의 합을 반환한다.
numbers = [1, 2, 3, 4]
print(sum(numbers)) # 출력: 10
- abs(x)
숫자의 절대값을 반환다. x가 복소수인 경우, 그 크기(magnitude)를 반환한다.
print(abs(-5)) # 출력: 5
print(abs(3 + 4j)) # 출력: 5.0 (sqrt(3^2 + 4^2))
- all(iterable)
이터러블의 모든 요소가 참이면 True를, 그렇지 않으면 False를 반환한다.
print(all([True, True, True])) # 출력: True
print(all([True, False, True])) # 출력: False
- any(iterable)
이터러블 중 하나라도 참이 있으면 True를, 모두 거짓이면 False를 반환한다.
print(any([False, True, False])) # 출력: True
print(any([False, False, False])) # 출력: False
- bin(x)
정수를 이진 문자열로 변환한다. 결과는 0b로 시작다.
print(bin(10)) # 출력: 0b1010
- hex(x)
정수를 16진수 문자열로 변환한다. 결과는 0x로 시작한다.
print(hex(255)) # 출력: 0xff
- chr(x)
정수 x에 대한 유니코드 문자를 반환한다.
print(chr(97)) # 출력: 'a
- ord(c)
문자에 대한 유니코드 정수 값을 반환한다.
print(ord('a')) # 출력: 97
- pow(x, y)
x에 대한 y 제곱을 반환한다.
print(pow(2, 3)) # 출력: 8
- math.sqrt(x)
x의 제곱근을 반환한다.
import math
print(math.sqrt(16)) # 출력: 4.0
- round(x)
숫자를 반올림한 결과를 반환한다. 두 번째 인자로 소수점 이하 자릿수를 지정할 수 있다.
print(round(3.14159, 2)) # 출력: 3.14
8. 클래스
✓ 클래스 선언과 인스턴스 생성
class 키워드로 새 타입을 정의할 수 있고, 클래스 이름을 호출하면 인스턴스가 생성된다.
class Person:
pass # pass는 블록이 아직 미구현 상태라 비어있을 때 쓸 수 있는 no-op 문법
p = Person()
✓ __init__()와 self
__init__은 클래스의 생성자이며, self는 해당 인스턴스 자신을 가르킨다.
class User:
def __init__(self, name, age): # 생성자
self.name = name # 인스턴스 변수
self.age = age
u = User("Alice", 30)
✓ 클래스 메서드 종류: 인스턴스 메서드, 클래스 메서드, 정적 메서드
파이썬 클래스에서 메서드는 데코레이터 사용 여부에 따라 동작 방식이 달라진다.
- 인스턴스 메서드는 항상 첫 번째 인자로 인스턴스 자기 자신인 self를 받는다.
- 클래스 메서드는 @classmethod 데코레이터를 사용해 클래스 자기 자신인 cls를 인자로 받는다.
- 정적 메서드는 @staticmethod 데코레이터를 사용하며, 인스턴스나 클래스 상태에 의존하지 않는 유틸리티 함수로 사용된다.
class Math:
factor = 10
def mul(self, x): # 인스턴스 메서드 (self)
return x * self.factor
@classmethod
def cmul(cls, x): # 클래스 메서드 (cls)
return x * cls.factor
@staticmethod
def add(a, b): # 정적 메서드 (self/cls 없음)
return a + b
✓ 클래스 변수와 인스턴스 변수
클래스 변수 예시. 인스턴스를 여러 개 만들어도 각 인스턴스는 동일한 클래스 변수를 공유한다.
class Counter:
count = 0 # 클래스 변수 (static과 유사)
def __init__(self):
Counter.count += 1 # 클래스 변수 접근
a = Counter()
b = Counter()
print(a.count) # 2
print(b.count) # 2
print(Counter.count) # 2
인스턴스 변수 예시. 인스턴스 변수는 각 인스턴스마다 독립적이다.
class Counter:
def __init__(self):
self.count = 0 # 인스턴스 변수 (static 아님)
a = Counter()
b = Counter()
a.count += 1
print(a.count) # 1
print(b.count) # 0 (공유되지 않음)
✓ 상속과 오버라이딩
자식 클래스를 선언할 때 괄호 안에 부모 클래스를 지정하면 상속을 받을 수 있다. 상속을 통해 부모 클래스의 속성과 메서드를 자식 클래스에서 그대로 사용할 수 있으며, super()를 사용하면 부모 클래스의 메서드나 생성자를 호출할 수 있다.
자식 클래스에서 부모 클래스와 같은 이름의 메서드를 정의하면, 해당 메서드는 부모의 메서드를 오버라이딩한다. 이 경우 부모 메서드는 기본적으로 가려지며, 필요하다면 super()를 통해 부모의 구현을 함께 사용할 수 있다.
class Parent:
def __init__(self):
print("Parent 생성자")
def func(self):
print("Parent func() 호출")
class Child(Parent):
def __init__(self):
# 부모 생성자 호출을 원하는 경우 자동으로 호출이 안되니 명시적으로 호출해주어야 한다.
super().__init__()
print("Child 생성자")
def func(self):
print("Child func() 호출")
obj = Child()
obj.func()
'프로그래밍 > Python' 카테고리의 다른 글
| Pyside6 ] 개발 환경 설정 with VSCode (0) | 2024.06.08 |
|---|---|
| Python ] 코드 실행 시간 ms 단위로 측정하기 + datetime 모듈 사용법 (0) | 2024.06.03 |
| Python ] struct 모듈 (0) | 2023.03.31 |
| Python ] import (상위/하위/동일 폴더, 다른 경로) (0) | 2023.03.25 |
| Python ] if __name__ == '__main__': (0) | 2023.03.25 |

