이어서 이중 연결 리스트로 구현한 도서 관리 프로그램의 노드 삭제, 삽입정렬, 메모리 할당해제 기능 등을 소개한다.
2022.05.02 - [Language/C] - [C언어] 프로젝트 : 이중 연결 리스트로 구현한 도서 관리 프로그램 - (5) - 링크드 리스트와 파일 입출력, 노드 추가
깃허브 주소 : https://github.com/joeteo/BookManager_C
GitHub - joeteo/BookManager_C: Book Mangager program in C
Book Mangager program in C. Contribute to joeteo/BookManager_C development by creating an account on GitHub.
github.com
void deleteMenu(LIST* ptrlist); // 삭제할 도서를 도서명으로 검색하여 검색 결과 모두, 혹은 특정 도서만 삭제할 수 있게끔 선택하게 하는 함수
void deleteMenu(LIST* ptrlist) {
char chk = 0;
int numToDelete = 0;
if (listCount(ptrlist) > 0) {
printf("------------------------------------------------------------------------------\n");
printf(" 삭제하고자 하는 도서를 검색하세요\n\n");
int* searchedNum = (int*)calloc(listCount(ptrlist), sizeof(int)); // 검색결과번호 담을 목적으로 도서개수만큼 int 메모리 할당
if (searchedNum != NULL) { // calloc 반환이 0인 경우 예외처리
listSearchForDel(ptrlist, searchedNum); // 삭제용 검색 함수
if (searchedNum[0] == 0) { // 검색 결과가 없을 때
printf("\n 메뉴로 돌아갑니다......");
system("pause");
}
else if (searchedNum[1] == 0 || listCount(ptrlist) == 1) { // 검색 결과가 1개일 때 || 검색결과가 있으면서 도서 데이터 1개일 때
printf("\n 정말 삭제하시겠습니까? Yes [1] / No [0] ... [ ]\b\b");
scanf_s("%hhd", &chk);
if (chk == 1 ) {
deleteNode(ptrlist, searchedNum[0]); // 노드 삭제 함수 호출
printf("\n 삭제가 완료되었습니다...");
system("pause");
}
else {
printf("\n 삭제하지 않고 메뉴로 돌아갑니다...");
system("pause");
}
}
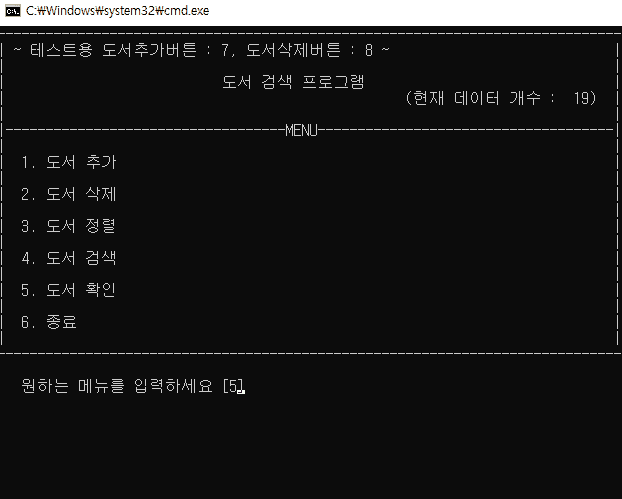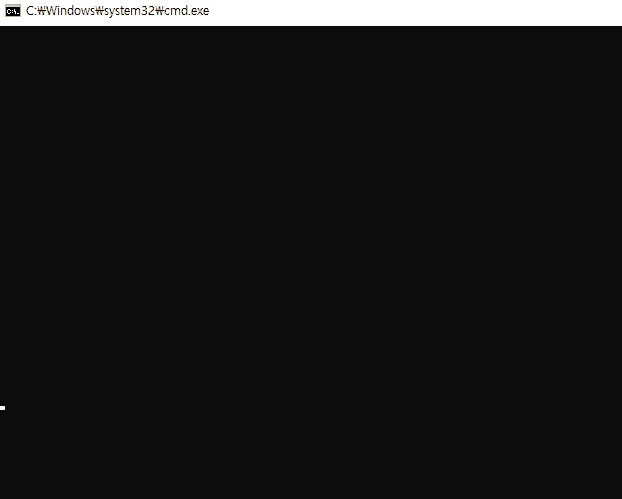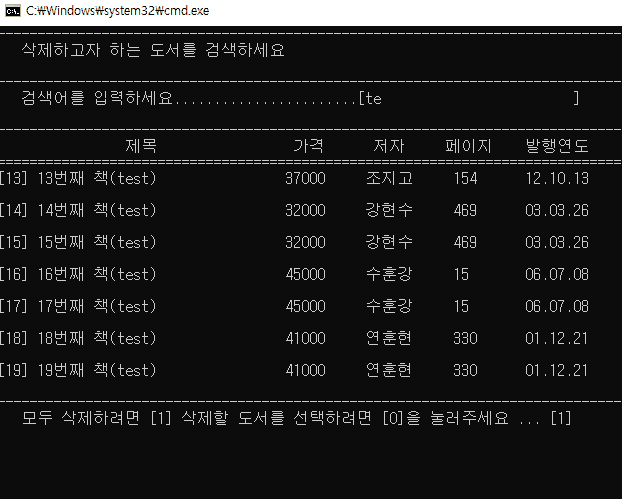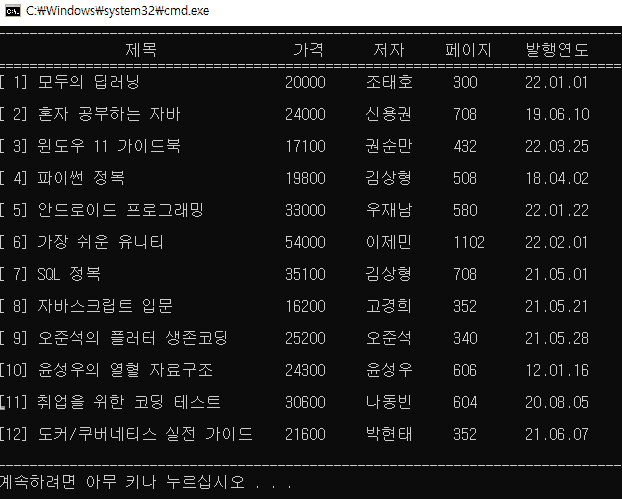
else { // 검색 결과가 여러개 일 때
printf(" 모두 삭제하려면 [1] 삭제할 도서를 선택하려면 [0]을 눌러주세요 ... [ ]\b\b");
scanf_s("%hhd", &chk);
if (chk == 1) {
int i = 0;
while (searchedNum[i] != 0 && listCount(ptrlist) > 0) { // 도서 데이터 개수 이하 반복하면서 검색 결과 갯수만큼
deleteNode(ptrlist, searchedNum[i] - i); // 검색 결과 모두 삭제(지울때마다 도서번호-1)
i++;
}
printf("\n 삭제가 완료되었습니다...");
system("pause");
return;
}
else if (chk != 0) {
printf("\n 삭제하지 않고 메뉴로 돌아갑니다...");
system("pause");
return;
}
printf("\n 삭제할 도서 번호를 입력해주세요 ... [ ]\b\b\b\b");
scanf_s("%d", &numToDelete);
for (int i = 0; i < listCount(ptrlist); i++) { // 입력한 번호가 검색결과에 있는 번호인지 검사
if (searchedNum[i] == numToDelete) {
chk = 1;
}
}
if (chk == 0 || numToDelete <= 0) { // 0 또는 음수 또는 리스트에 없는 번호 입력시 예외처리
printf("\n 잘못 입력하셨습니다. 메뉴로 돌아갑니다...");
system("pause");
}
else {
printf("\n 정말 삭제하시겠습니까? Yes [1] / No [0] ... [ ]\b\b");
scanf_s("%hhd", &chk);
if (chk == 1) {
deleteNode(ptrlist, numToDelete); // 노드 삭제 함수 호출
printf("\n 삭제가 완료되었습니다...");
system("pause");
}
else {
printf("\n 삭제하지 않고 메뉴로 돌아갑니다...");
system("pause");
}
}
}
free(searchedNum); // searchedNum 메모리 할당 해제
}
}
else {
printf("------------------------------------------------------------------------------\n");
printf(" 출력할 데이터가 없습니다. 메뉴로 돌아갑니다...\n\n ");
system("pause");
}
}
- 이건 예외처리가 많이 필요했다. 일단 listCount 개수가 0이라면 제일 먼저 빠져나간다. 아니라면 searchedNum 이라고 검색결과를 담을 int형 배열을 listCount 수만큼 메모리 할당해주고 listSearchForDel이라는 삭제용 검색함수를 호출하는데 검색함수와 거의 내용이 똑같다. 다른점은 검색결과가 일치하는 도서가 있을 때마다 searchedNum 배열 요소에 도서번호를 기록해 놓는다. calloc으로 할당했으니, 예를 들어 도서개수가 총 6개 있는데 검색에 일치하는 결과값이 3개가 나온다면 [0][1][2] 인덱스에는 해당 도서번호가 순서대로 들어있고 [3][4][5]는 0으로 채워져있을 것이다.
- 그리고 검색 결과가 여러개 나올 때 모두 삭제할 수 있는 기능을 추가했는데, 검색한 순서대로 앞쪽 번호부터 노드를 삭제하면 그 뒷 노드들은 한칸씩 땡겨지니까 searchedNum[i] - i 로 반복하며 삭제해야 했다.
int i = 0;
while (searchedNum[i] != 0 && listCount(ptrlist) > 0) { // 도서 데이터 개수 이하 반복하면서 검색 결과 갯수만큼
deleteNode(ptrlist, searchedNum[i] - i); // 검색 결과 모두 삭제(지울때마다 도서번호-1)
i++;
}
void deleteNode(LIST* ptrlist, int numToDelete); // 특정 노드 삭제
void deleteNode(LIST* ptrlist, int numToDelete) { // 특정 노드 삭제
int i = 1;
ptrlist->curr = ptrlist->head->next;
while (i!=numToDelete) { // curr이 삭제할 도서 노드를 가리킬 때까지 순회
ptrlist->curr = ptrlist->curr->next;
i++;
}
ptrlist->curr->prev->next = ptrlist->curr->next; // 삭제할노드의 직전 노드의 next가 삭제할노드의 다음 노드를 가리키게함
ptrlist->curr->next->prev = ptrlist->curr->prev; // 삭제할노드의 다음 노드의 prev가 삭제할노드의 직전 노드를 가리키게함
free(ptrlist->curr); // curr이 가리키고 있는 노드 메모리 할당 해제
(ptrlist->numOfData)--; // 노드 개수 줄임
}- 매개변수로 해당 데이터노드의 순서번호가 온다. curr이 계속 다음칸으로 이동하다가 삭제할 노드를 가리키게 되는 순간 while문을 탈출하고 삭제할 노드의 앞노드와 뒷노드를 서로 연결시켜준뒤 curr이 가리키고 있던 노드는 할당 해제하고 노드 개수를 줄인다.
- 그림으로 그리면 이런 느낌


void sortMenu(LIST* ptrlist); // 정렬 메뉴
void sortMenu(LIST* ptrlist) {
int select;
printf("|----------------------------------------------------------------------------|\n");
printf("| |\n");
printf("| 무엇으로 정렬하시겠습니까? |\n");
printf("| |\n");
printf("| 1. 가격 순 |\n");
printf("| |\n");
printf("| 2. 발행연도 순 |\n");
printf("| |\n");
printf("| 3. 페이지 순 |\n");
printf("| |\n");
printf("| 4. 도서명 순 |\n");
printf("| |\n");
printf("| 5. 저자명 순 |\n");
printf("------------------------------------------------------------------------------\n\n");
if (listCount(ptrlist) <= 0) {
printf(" 출력할 데이터가 없습니다. 메뉴로 돌아갑니다...\n\n ");
system("pause");
return;
}
printf(" 원하는 메뉴를 입력하세요 [ ]\b\b");
scanf_s("%d", &select);
if (select > 0 && select < 6) {
LIST tempList; // 원본값을 훼손하지 않기 위한 정렬용 복사본
listInit(&tempList); // 리스트 초기설정
copyList(&tempList, ptrlist); // 리스트 복사, listInit 후 사용
if (select == 1) insertionSort(&tempList, (_comp)compare_price);
else if (select == 2) insertionSort(&tempList, (_comp)compare_date);
else if (select == 3) insertionSort(&tempList, (_comp)compare_page);
else if (select == 4) insertionSort(&tempList, (_comp)compare_title);
else if (select == 5) insertionSort(&tempList, (_comp)compare_author);
system("cls");
listPrint(&tempList); // 정렬 데이터 출력
freeAllNode(&tempList); // 임시리스트 메모리 전체 할당 해제
}
else {
rewind(stdin);
printf(" 잘못 입력하셨습니다. 메뉴로 돌아갑니다...");
system("pause");
}
}- listCount가 0개라면 바로 main으로 돌아가고 아닌 경우 원하는 정렬기준을 입력받는다. 원본 리스트는 도서가 등록된 순서를 유지하고 있는데 그 순서를 훼손하지 않기위해 정렬용 리스트 복사본을 먼저 만들고 초기설정후 copyList함수로 리스트 복사 완료한뒤에 insertionSort 함수를 호출하는데 인수로는 리스트 복사본이랑 미리 만들어준 정렬기준 함수의 주소(=>함수포인터)를 인수로 넘긴다.
- 배열의 이름이 마치 배열의 시작주소인 것처럼 함수의 이름이 함수의 주소이다.
- 정렬을 마친 후 리스트 복사본을 출력하고 복사본 전체를 메모리에서 할당 해제한다.
void copyList(LIST* destination, LIST* source); // 리스트 복사 함수
void copyList(LIST* destination, LIST* source) { // 리스트 복사
source->curr = source->head->next; // 소스리스트 curr이 1번째 데이터 노드를 가리키게함
while (source->curr != source->tail) { // 소스리스트 curr이 테일을 가리킬때까지 반복
NODE* newDestNode = (NODE*)calloc(1, sizeof(NODE)); // 새 노드 생성, 임시 포인터인 newDestNode에 주소값 대입
if (newDestNode != NULL) { // malloc 반환이 NULL인 경우 예외처리
memcpy(newDestNode, source->curr, sizeof(NODE)); // 메모리 복사
newDestNode->prev = destination->tail->prev; // 목적지 리스트 꼬리에 복사된 노드 연결
destination->tail->prev->next = newDestNode;
newDestNode->next = destination->tail;
destination->tail->prev = newDestNode;
(destination->numOfData)++; // 데이터 개수 증가
source->curr = source->curr->next; // 소스리스트의 curr을 다음칸으로 이동
}
else printf("메모리 할당에 실패하였습니다.");
}
}- 리스트 복사함수를 호출하기 전에 먼저 헤드테일 더미노드를 만드는 등 초기설정부터 해주어야한다.
- 매개변수는 (목적 리스트, 소스 리스트)이고, 소스리스트에서 목적 리스트로 복사한다.
- 함수 안쪽은 addNode 함수랑 비슷하다. 다른 점은, 소스 리스트의 curr을 한칸 씩 이동하면서 memcpy로 소스 노드의 내용을 새로만든 노드에 복사해준 뒤 목적 리스트 꼬리쪽에 삽입을 반복한다.
정렬 기준 함수들. 반환값은 int 이고 매개변수는 노드 포인터 2개이다. arg1이 크면 양수 반환 arg2가 작으면 음수반환, arg1과 arg2가 똑같으면 0반환이라는 규칙을 가지고 만들었다.
// 검색 기준 여기부터
int compare_price(const NODE* arg1, const NODE* arg2) {
if (arg1->price != arg2->price) return (arg1->price - arg2->price);
else return 0;
}
int compare_page(const NODE* arg1, const NODE* arg2) {
if (arg1->page != arg2->page) return (arg1->page - arg2->page);
else return 0;
}
int compare_date(const NODE* arg1, const NODE* arg2) {
if (arg1->date.year != arg2->date.year) return (arg1->date.year - arg2->date.year);
else if (arg1->date.month != arg2->date.month) return (arg1->date.month - arg2->date.month);
else if (arg1->date.day != arg2->date.day) return (arg1->date.day - arg2->date.day);
else return 0;
}
int compare_title(const NODE* arg1, const NODE* arg2) {
return strcmp(arg1->title, arg2->title);
}
int compare_author(const NODE* arg1, const NODE* arg2) {
return strcmp(arg1->author, arg2->author);
}
// 검색 기준 여기까지
헤더파일에는 이렇게 함수포인터 별칭 _comp를 typedef로 선언해 두었다.

insertionSort함수 내부에서는 함수의 주소를 함수포인터 매개변수로 받아서 쓴다. 근데 위에 보이 듯이 함수포인터 선언를 void* void* 형으로 해두었기 때문에..

sortMenu 함수에서 인수 전달할 때 앞에 (_comp)이런식으로 캐스팅해줘야 했다.

사실 정렬기준 함수들이 전부 NODE* NODE*매개변수여서 이렇게 할 필요가 전혀 없다.. 걍 애초에 함수포인터를 NODE* NODE* 형으로 선언해주면 형변환을 안해줘도 된다. 이렇게↓


근데 왜 굳이 void* void* 로 선언해서 형변환을 해줬냐하면 그게 더 범용성이 좋아보여서.. 글고 C언어에서 기본제공하는 qsort(퀵정렬)함수의 매개변수가 이런 형태로 되어 있어서 나중에 내가 보고 참고할 때 좋을 거 같아서 그랬다.
아니면 이런 방법도 있다.

이런식으로↓ 정렬기준 함수 또한 void* void*형으로 맞춰주고 내부에서 다시 (NODE*)로 캐스팅해서 쓰는방법

이건 구조체라서 그런거고, 만약 바로 값에 대한 주소를 void* void*로 받아왔다면 해당 자료형포인터에 맞게 캐스팅해준 뒤 그 앞에 애스터리스크 하나 더 붙이면 바로 값을 비교해서 결과를 반환할 수도 있다. ex. *((int*)arg1)
void insertionSort(LIST* ptrlist, _comp criteria); // 삽입 정렬 함수
void insertionSort(LIST* ptrlist, _comp criteria) { // 삽입정렬
NODE* compNode = NULL; // 정렬용 임시 포인터, curr 앞 쪽을 역순으로 순회하며 대소비교
ptrlist->curr = ptrlist->head->next->next; // curr이 2번째 노드 가리킴
compNode = ptrlist->head->next; // compNode가 1번째 노드 가리킴
while (ptrlist->curr != ptrlist->tail) { // curr이 테일더미 갈때까지 반복
if (criteria(ptrlist->curr, compNode) >=0) { // 앞쪽은 이미 정렬된 자료라서 curr데이터가 더 크거나 같으면 암것도 안함
ptrlist->curr = ptrlist->curr->next; // 스왑을 안했으면 바로 curr 한칸 뒤로
}
else {
// curr데이터가 작은 동안 compNode가 앞쪽으로 이동하는데 1번째 데이터노드까지만
while (compNode != ptrlist->head->next && criteria(ptrlist->curr, compNode) < 0) {
compNode = compNode->prev;
}
NODE* temp = ptrlist->curr; // curr의 위치 저장용
putNPushNode(compNode, ptrlist->curr); // curr 노드 알맞은 위치에 끼워 넣기
ptrlist->curr = temp->next; // 끼워넣기직전 저장해둔 curr의 다음칸으로 옮김
}
compNode = ptrlist->curr->prev; // compNode는 curr보다 한칸 앞
}
}- curr은 두번째 데이터노드부터 마지막 데이터 노드에 갈때까지 반복하고 compNode 포인터는 curr 앞쪽을 역방향으로 이동하며 대소비교를 한다. 삽입정렬에서 curr 앞부분은 이미 정렬된 상태이기 때문에 curr 노드가 삽입될 적절한 위치만 찾아 끼워넣으면 된다. (curr데이터보다 compNode데이터가 크면 compNode는 역방향으로 이동하고 curr데이터보다 compNode데이터가 더 작으면 바로 while문을 탈출한다.)
- insertionSort의 두번째 매개변수는 내가 헤더에서 typedef 해둔 함수포인터 타입 _comp이고 매개변수명은 criteria로 해줬다. 문장을 순서대로 실행하다가 criteria를 만나면 내가 인수로 넣어준 주소값을 가지는 함수를 호출하게 된다. 이렇게 전달된 인자에 따라 달리 동작하게끔 할 수 있는게 함수포인터의 장점이다. 그래서 정렬기준에 대한 내용은 다 따로 함수화하고 삽입정렬함수 내부는 간략하게 구성할 수 있었다.
- curr의 위치를 temp에 잠시 저장해 두고(끼워넣고나면 prev/next값이 바뀔테니) putNPushNode함수를 호출해 끼워 넣은 뒤 curr은 끼워넣기 직전 자리의 다음칸으로 옮긴다.



void putNPushNode(NODE* compNode, NODE* curr); // 노드 원하는 자리에 끼워 넣는 함수
void putNPushNode(NODE* compNode, NODE* curr) { // 노드 원하는 자리에 끼워 넣기
NODE* temp = (NODE*)malloc(sizeof(NODE)); // 데이터 보존 위한 임시 노드
if (temp != NULL) { // malloc 반환이 NULL인 경우 예외처리
memcpy(temp, curr, sizeof(NODE));
// curr을 compNode 앞에 끼워 넣고 원래 curr 앞쪽과 뒤쪽노드를 서로 연결해줌
curr->prev = compNode->prev;
compNode->prev->next = curr;
curr->next = compNode;
compNode->prev = curr;
temp->prev->next = temp->next;
temp->next->prev = temp->prev;
free(temp); // temp 메모리 할당 해제
}
else printf("메모리 할당에 실패하였습니다.");
}- 삽입정렬을 위해 curr이 가르키는 노드를 특정 위치에 끼워 넣기 위해 만든 함수이다.
- 일단 memcpy로 curr이 가르키는 노드를 temp 포인터로 만든 노드에 복사해 둔다. (curr의 next/prev값을 기억해두기 위해)
- curr을 compNode 앞에 끼워 넣고 원래 curr이 있던 곳의 앞쪽과 뒤쪽노드를 서로 연결해 준뒤 temp는 해제한다.
void delLastNode(LIST* ptrlist); // 마지막 데이터 노드를 삭제하는 함수
void delLastNode(LIST* ptrlist) { // 마지막 도서 삭제, freeAllNode에서도 쓰고 테스트용삭제로도 씀
ptrlist->curr = ptrlist->tail->prev; // 테일더미노드의 prev값을 curr에 대입
if (ptrlist->curr == ptrlist->head) { // curr이 헤드더미노드를 가리키면(=데이터가 없으면) 아무것도 안함
}
else {
ptrlist->curr->prev->next = ptrlist->curr->next; // 마지막 데이터노드의 직전 노드의 next가 테일더미노드를 가리키게함
ptrlist->curr->next->prev = ptrlist->curr->prev; // 테일더미노드의 prev가 마지막 데이터노드의 직전 노드를 가리키게함
free(ptrlist->curr); // curr이 가리키는 마지막 데이터노드 메모리 할당 해제
(ptrlist->numOfData)--; // 노드 개수 줄임
}
}- 위의 특정노드를 삭제하는 deleteNode는 첫노드부터 시작해서 뒤로가기 때문에 마지막 노드 삭제전용을 따로 만들었다. 테스트용 도서삭제버튼을 눌렀을 때 이 함수가 호출되고 아래의 freeAllNode 함수도 이 함수를 사용한다.
void freeAllNode(LIST* ptrlist); // 리스트의 모든 노드를 메모리에서 할당 해제하는 함수
void freeAllNode(LIST* ptrlist) { // 리스트의 모든 노드 free
while (listCount(ptrlist) > 0) { // 도서 개수 만큼 삭제 (delLastNode함수 내부에서 listCount--함)
delLastNode(ptrlist); // 마지막 도서를 삭제하는 함수 호출
}
free(ptrlist->head); // 헤드더미노드 메모리 할당 해제
free(ptrlist->tail); // 테일더미노드 메모리 할당 해제
}- 리스트 포인터를 매개변수로 받아 모든 노드를 free해준다.
- listCount개수가 0보다 클 동안은 delLastNode함수를 반복 호출한다. delLastNode함수 내부에서 listCount를 -- 하니까 데이터노드를 다 지우고 나서 멈춘다.
- 마지막으로 헤드와 테일 더미노드도 메모리에서 할당 해제해준다.
정말 끝!
'프로젝트(Project) 모음' 카테고리의 다른 글
| STM32 ] GPS 를 이용한 자율주행 메카넘휠 (2) | 2022.07.12 |
|---|---|
| STM32 프로젝트 , 팩맨 게임 ( ADC in DMA mode 로 조이스틱 이용한 방향제어 , I2C LCD , Timer 인터럽트 및 PWM 사용 ) (5) | 2022.05.31 |
| [ 아두이노 ] 핸드 제스처로 RC카 제어 ( 9축 기울기센서 , 블루투스 모듈 사용 ) (18) | 2022.05.17 |
| [ C언어 ] 프로젝트 : 이중 연결 리스트로 구현한 도서 관리 프로그램 - (5) - 링크드 리스트와 파일 입출력 , 노드 추가 (0) | 2022.05.02 |
| AI 프로젝트 , 두더지 게임 with Mediapipe and Python (2) | 2022.04.24 |



