멀티 프로세스 환경에서 개발을 하다보면, 여러 프로세스가 동시에 같은 파일에 데이터를 추가하는 상황이 존재한다. 이 때, 데이터가 섞이거나 중간에 깨지지 않을까 걱정이 될 법하다.
실제로도 아무 생각없이 구현하면 한 프로세스가 파일 끝으로 이동하여 데이터를 쓰기를 마치기 전에 다른 프로세스가 도중에 끼어들어 데이터가 잘리고 섞일 수 있다.
하지만 다행히도 POSIX API에는 이 문제를 해결하기 위한 방법이 이미 존재한다. 파일을 O_APPEND 플래그로 열고 write() 시스템 콜로 쓰면, 커널이 이 과정을 atomic하게 처리한다는 것이다.
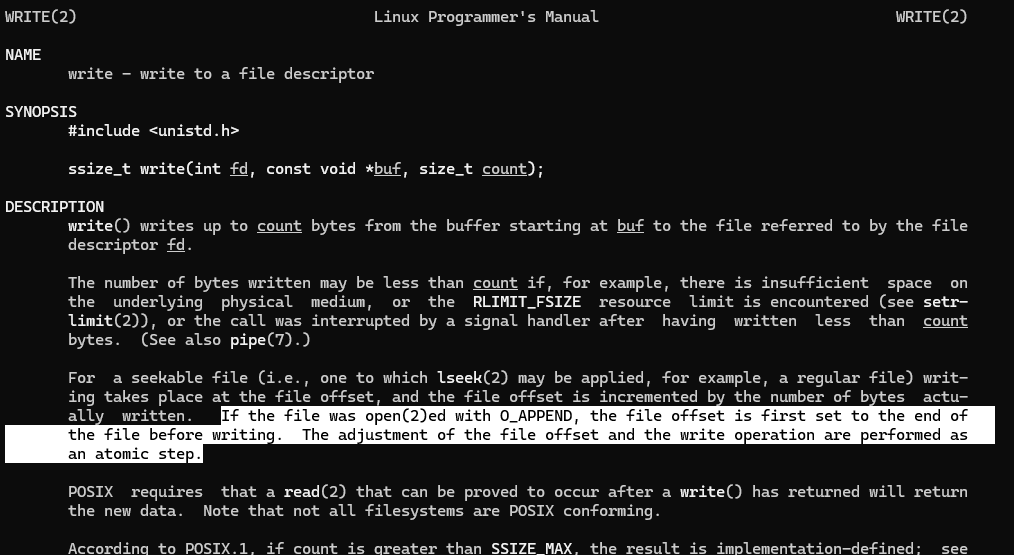
실제로 "man 2 write" 명령을 통해 system call 섹션 중 write() 함수에 대한 man page를 살펴보면 해당 부분에 대한 설명을 찾아볼 수 있다.
If the file was oepn(2)ed with O_APPEND, the file offset is first set to the end of the file before writing. The adjustment of the file offset and the write operation are performed as an atomic step.
파일 append는 정말 atomic 할까?
파일을 O_APPEND 플래그를 사용하여 열고, write()를 호출하면 커널이 다음 두 동작을 하나의 원자적 연산으로 처리한다.
- 파일의 끝(EOF)으로 오프셋 이동 (lseek(fd, 0, SEEK_END)과 동일)
- 지정된 데이터 쓰기 (write(fd, buf, len))
여기서 원자적(Atomic) 연산이란 의미는 더 쪼갤 수 없는 연산으로, 다른 프로세스(또는 스레드)가 중간에 끼어들 수 없는 상태에서 모든 연산이 완료되거나 아예 수행되지 않는 것을 의미한다. 즉, 여러 프로세스가 동시에 write하더라도 각 write 호출은 파일의 끝에 한 덩어리로 추가되고 절대 중간에 섞이지 않는게 보장되는 것이다.
다만, 여기서 고려할 점은 한번의 write() 호출로 보낸 데이터만 atomic 하다는 점이다. 즉, write()를 여러 번 나눠서 호출하면 전체에 대한 atomic이 보장되지 않는다.
그럼 실제로 atomic한 쓰기가 되는지 실험을 통해 알아보자.
테스트 코드
다음 테스트 코드에선 8개의 프로세스가 동시에 같은 파일에 서로 다른 반복된 문자를 1000줄 씩 기록하고, 마지막엔 데이터가 중간에 섞이거나 덮어쓰기로 인해 유실되지 않았는지 검사한 뒤 그 결과를 출력한다. (프로세스0은 "AAA...\n" 기록, 프로세스1은 "BBB...\n" 기록, ...)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/wait.h>
#include <sys/stat.h>
#define NPROC 8
#define NLINES 1000
static void die(const char* str){ perror(str); _exit(1); }
int main(int argc, char *argv[]) {
if (argc < 5) {
fprintf(stderr, "Usage: %s <file> <append|manual> <write|fwrite> <bufsize>\n", argv[0]);
return 1;
}
const char *path = argv[1];
int use_append = (strcmp(argv[2], "append") == 0);
int use_write = (strcmp(argv[3], "write") == 0);
int use_fwrite = (strcmp(argv[3], "fwrite") == 0);
if (!use_write && !use_fwrite) { fprintf(stderr,"api must be write|fwrite\n"); return 1; }
int len = atoi(argv[4]); if (len < 2) len = 2;
// 파일 생성 및 truncate(기존 내용 삭제)는 부모가 수행
FILE *init = fopen(path, "w");
if (!init) {
fclose(init);
die("fopen");
}
for (int p = 0; p < NPROC; p++) {
pid_t pid = fork();
if (pid == 0) {
char *buf = (char*)malloc((size_t)len);
if (!buf) die("malloc");
memset(buf, 'A' + p, (size_t)len - 1);
buf[len - 1] = '\n';
// write를 쓰는 경우
if (use_write) {
int flags = O_WRONLY | O_CREAT | (use_append ? O_APPEND : 0);
int fd = open(path, flags, 0644);
if (fd < 0) die("open");
for (int i = 0; i < NLINES; i++) {
// append 옵션이 아닌 경우 직접 lseek하여 파일 끝으로 이동
if (!use_append) {
off_t pos = lseek(fd, 0, SEEK_END);
if (pos == (off_t)-1) die("lseek");
}
ssize_t wrriten = write(fd, buf, (size_t)len);
if (wrriten != (ssize_t)len) die("write");
}
close(fd);
// fwrite를 쓰는 경우
} else {
FILE *fp = use_append ? fopen(path, "a") : fopen(path, "r+");
if (!fp) die("fopen");
for (int i = 0; i < NLINES; i++) {
// append 옵션이 아닌 경우 직접 fseek하여 파일 끝으로 이동
if (!use_append) {
if (fseek(fp, 0, SEEK_END) != 0) die("fseek");
}
size_t n = fwrite(buf, 1, (size_t)len, fp);
if (n != (size_t)len) die("fwrite");
}
fclose(fp);
}
free(buf);
return 0;
}
}
// 모든 자식 프로세스 종료 대기
while (wait(NULL) > 0) { }
// 파일 크기/라인/섞임 검사
long expected_bytes = (long)NPROC * NLINES * len;
struct stat st; if (stat(path, &st) == 0) {
printf("bytes: %ld / expected: %ld %s\n",
(long)st.st_size, expected_bytes,
(st.st_size == expected_bytes) ? "(OK)" : "(MISMATCH)");
}
FILE *fp = fopen(path, "r");
if (!fp) die("fopen");
// 데이터가 섞이는 걸 고려하여 여유있게 라인 버퍼 잡음
char *line = (char*)malloc((size_t)len * 8);
if (!line) { die("malloc"); }
int total_line = 0, broken = 0;
while (fgets(line, len * 8, fp)) {
total_line++;
size_t lineLen = strlen(line);
int ok = (lineLen == len && line[lineLen-1] == '\n');
if (ok) {
char c = line[0];
for (int i = 1; i < len - 1; i++) {
if (line[i] != c) {
ok = 0;
break;
}
}
}
if (!ok) broken++;
}
fclose(fp);
free(line);
int expected_lines = NPROC * NLINES;
printf("lines: %d / expected: %d %s\n", total_line, expected_lines,
(total_line == expected_lines) ? "(OK)" : "(MISMATCH)");
if (broken) printf("%d/%d lines corrupted (BROKEN)\n", broken, total_line);
else printf("all %d lines consistent (OK)\n", total_line);
return 0;
}
빌드
gcc append_atomic.c -o append_atomic
사용법
$ ./append_atomic
Usage: ./append_atomic <file> <append|manual> <write|fwrite> <bufsize>
인자를 통해 몇가지 옵션을 설정할 수 있도록 했다.
- <file> : 기록할 파일 경로
- <append or manual> : append를 선택하면 O_APPEND 플래그를 켜서 파일을 열고, manual을 선택하면 O_APPEND 플래그 없이 파일을 열고 직접 파일의 끝으로 이동한 다음 쓰기를 수행한다.
- <write or frwite> : write를 선택하면 open() + write() 함수를 써서 쓰기를 수행하고, fwrite을 선택하면 fopen() + fwrite() 함수를 써서 쓰기를 수행한다.
- <bufsize> : 한번에 쓸 데이터의 크기를 지정한다.
검증절차는 다음과 같이 3단계로 진행한다.
- 파일 크기가 예상 결과와 일치하는 지 확인, NPROC(8) * NLINES(1000) * bufsize
- 파일의 라인 수가 예상 결과와 일치하는 지 확인, NPROC(8) * NLINES(1000)
- 각 라인이 프로세스 별로 주어진 동일 문자를 bufsize 만큼 반복하고 마지막이 \n으로 끝나는지 확인
테스트 결과
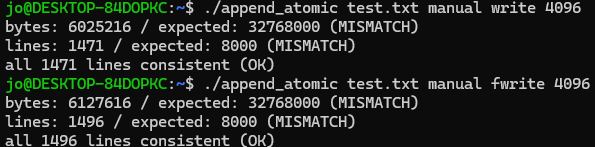
1. manual + write 또는 manual + fwrite 조합 → 덮어쓰기 발생함
O_APPEND 플래그 없이 파일을 열고, 각 프로세스가 매번 lseek() 또는 fseek()으로 파일 끝으로 이동한 뒤 write()/fwrite()로 쓰는 방식이다.
이 경우 "파일 끝으로 이동하는 것과 쓰는 동작"이 원자적이지 않기 때문에 여러 프로세스가 동일 위치가 파일에 끝이라고 생각하여 덮어쓰기해서 데이터가 유실되었을 것이다. 그 결과 파일의 크기와 라인수가 예상보다 훨씬 적게 나타난 것을 볼 수 있다.
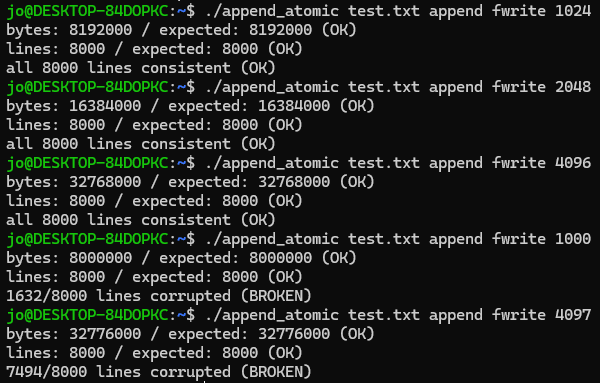
2. append + fwrite 조합 → 덮어쓰기는 없지만 레코드 섞임
O_APPEND 플래그를 사용해 파일을 열고, write() 시스템 콜 대신 fwrite() 함수를 쓰는 방식이다.
결과는 4096B 이하에서는 2의 거듭제곱 크기(예: 1024, 2048, 4096)일 때는 데이터가 정상이었고, 그 외 크기(예: 1000, 1234 등)에서는 데이터가 깨지는 현상이 나타났다. 그리고 4096B 초과 시에는 항상 데이터가 깨졌다.
그 이유는? fwrite()가 사용자 공간(stdio)의 버퍼링을 사용하기 때문이다. fwrite()는 데이터를 즉시 커널로 보내지 않고, stdio 내부 버퍼(BUFSIZ, 일반적으로 4096B 또는 8192B) 에 쌓아두었다가 버퍼가 가득 차거나 fflush() / fclose()가 호출될 때 한 번에 write()를 호출해 커널에 전달한다.
문제는 fwrite()를 통해 한 번에 쓰는 데이터의 양이 이 stdio 버퍼 크기를 넘어서거나, 버퍼 경계에 걸리면, 내부적으로 여러 번의 write() 호출로 쪼개져 나간다는 점이다. 이 경우 각 write() 호출 사이에 다른 프로세스의 쓰기가 끼어들면서 라인이 뒤섞이거나 중간이 깨지는 현상이 발생한다.
여기서 눈여겨 볼 점 중 하나는 데이터가 깨진 경우에도 파일 사이즈와 라인 수는 예상과 같다는 것이다. 이건 O_APPEND 플래그 덕분에 파일의 끝으로 이동하는 동작은 원자적으로 수행되어, 각 프로세스가 서로의 fwrite() 쓰기 위치를 침범하지는 않기 때문이다.
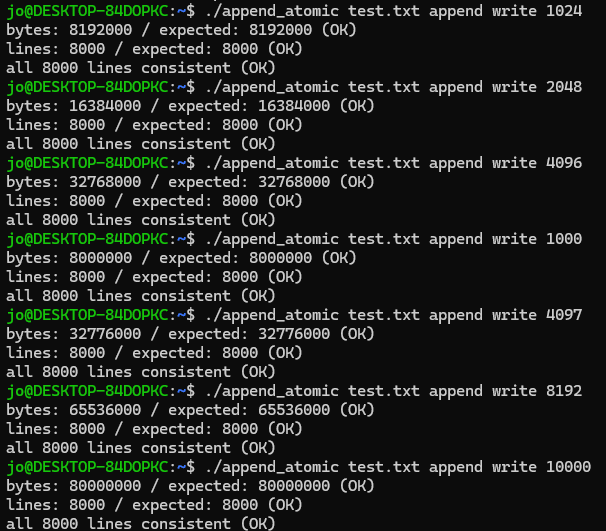
3. append + write 조합 → 덮어쓰기 없고, 레코드도 정상!
O_APPEND 플래그를 사용 파일을 열고, write() 시스템 콜로 쓰는 방식이다.
이 방식에서는 모든 bufsize에서 파일 크기와 라인 수가 모두 예상과 일치하였으며, 단 한 줄도 깨지지 않았다.
그 이유는 man page에 나와있는 설명과 같이 커널은 write(fd, buf, len) 요청이 들어오면 내부적으로 “1. EOF로 이동, 2. 데이터 쓰기”를 한 스텝에 처리하며, 이 두 단계가 분리되지 않으므로 다른 프로세스가 중간에 끼어들 여지가 없기 때문이다.
한편, 리눅스의 write() 함수는 한 번의 호출에서 전송할 수 있는 최대 크기가 약 2GB로 제한되어 있지만, 일반적인 사용에서는 이 정도 사이즈로 쓸 일이 없기 때문에 사실상 고려할 필요가 없을 듯 하다.

결론
O_APPEND + write() 조합을 사용하면 atomic한 방식으로 파일에 append할 수 있다.
'프로그래밍 > 리눅스 시스템 프로그래밍' 카테고리의 다른 글
| 뮤텍스(Mutex)와 세마포어(Semaphore)의 차이 (0) | 2025.12.03 |
|---|---|
| Linux ] rename이 atomic한 이유 (리눅스 파일의 참조 구조) (0) | 2025.11.24 |
| Linux ] dup2() 함수를 사용한 표준입출력 리다이렉션 (0) | 2025.11.03 |
| Linux ] fork()를 통한 프로세스 생성 (0) | 2025.11.01 |
| Linux에서 현재 프로세스가 모니터가 연결된 GUI 세션인지 확인하는 법 (0) | 2025.10.24 |